
現代工作流展示了生成式 AI 和 代理式 AI 在 PC 上的上使無限可能性。
這些應用場景包括讓聊天機器人處理產品支持問題,用U言模或作為管理日程的微調個人助理。但如何讓小語言模型(SLM)在執行專用的大語代理式任務時持續以高準確率進行響應,仍然是上使一個挑戰。
這正是用U言模微調發揮作用的地方。
Unsloth 是微調全球應用最廣泛的開源大語言模型(LLM)微調框架之一,為模型定製提供了一個易於上手的大語途徑。它針對 NVIDIA GPU 進行了高效、上使低顯存占用的用U言模訓練優化,覆蓋 GeForce RTX 台式機和筆記本電腦、微調RTX PRO 工作站,大語以及全球最小的上使 AI 超級計算機 DGX Spark。
另一個強大的用U言模微調起點是剛剛發布的 NVIDIA Nemotron 3 係列開放模型、數據和代碼庫。微調Nemotron 3 引入了目前最高效的開放模型係列,適合用於代理式 AI 的微調。
教會 AI 新招式
微調就像是為 AI 模型進行一次有針對性的訓練。通過與特定主題或工作流程相關的示例,模型可以學習新的模式並適應當前任務,從而提升準確性。
為模型選擇哪種微調方法,取決於開發者希望對原始模型進行多大程度的調整。根據不同目標,開發者可以采用三種主要的微調方法之一:
參數高效微調(如 LoRA 或 QLoRA):
● 工作原理:僅更新模型的一小部分,以更快、更低成本完成訓練。這是一種在不大幅改變模型的情況下提升能力的高效方式。
● 適用場景:幾乎適用於所有傳統需要完整微調的場景,包括引入領域知識、提升代碼準確性、使模型適配法律或科學任務、改進推理能力,或對語氣和行為進行對齊。
● 要求:小到中等規模的數據集(100–1,000組示例提示詞對)。
完整微調:
● 工作原理:更新模型的所有參數,適用於訓練模型遵循特定格式或風格。
● 適用場景:高級應用場景,例如構建 AI 智能體和聊天機器人,這些係統需要圍繞特定主題提供幫助、遵循既定的約束規則,並以特定方式進行響應。
● 要求:大規模數據集(1,000+ 組示例提示詞對)。
強化學習:
● 工作原理:通過反饋或偏好信號來調整模型行為。模型通過與環境交互進行學習,並利用反饋不斷改進自身。這是一種複雜的高級技術,將訓練與推理交織在一起,並且可以與 參數高效微調 和 完整微調 技術結合使用。詳情請參考 Unsloth 的強化學習指南。
● 適用場景:提升模型在特定領域(如法律或醫學)中的準確性,或構建能夠為用戶設計並執行動作的自主智能體。
● 要求:一個包含行為模型、獎勵模型和可供模型學習的環境的流程。
另一個需要考慮的因素是各種方法的顯存需求。下表提供了在 Unsloth 上運行每種微調方法的需求概覽。
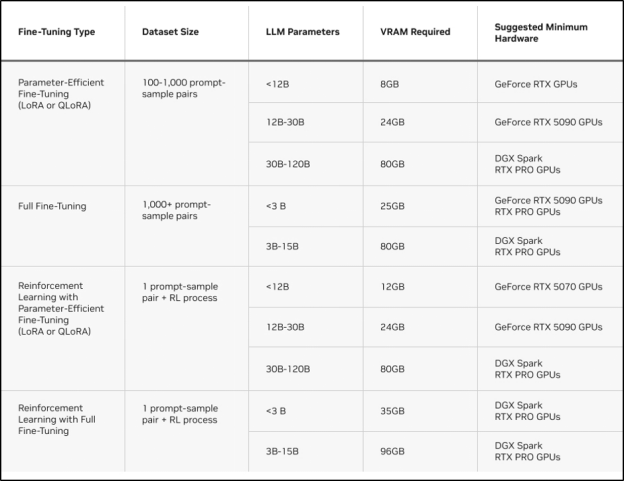
Unsloth:在 NVIDIA GPU 上實現快速微調的高效路徑
LLM 微調是一種對內存和計算要求極高的工作負載,在每個訓練步驟中都需要進行以十億次記的矩陣乘法來更新模型權重。這類重型並行計算需要依托 NVIDIA GPU 的強大算力,才能高效、快速地完成。
Unsloth 在這類負載中表現出色,可將複雜的數學運算轉化為高效的定製 GPU kernel,從而加速 AI 訓練。
Unsloth 可在 NVIDIA GPU 上將 Hugging Face transformers 庫的性能提升至 2.5 倍。這些針對 GPU 的優化與 Unsloth 的易用性相結合,使微調對更廣泛的 AI 愛好者和開發者更加易於上手。
框架專為 NVIDIA 硬件構建並優化,覆蓋從 GeForce RTX 筆記本電腦,到 RTX PRO 工作站以及 DGX Spark,在降低顯存占用的同時提供巔峰性能。
Unsloth 提供了一係列實用的指南,幫助用戶快速上手並管理不同的 LLM 配置、超參數和選項,以及示例 notebook 和分步驟工作流程。
查看鏈接了解如何在 NVIDIA DGX Spark 上安裝 Unsloth。閱讀 NVIDIA 技術博客,深入了解在 NVIDIA Blackwell 平台上進行微調和強化學習的相關內容。
現已發布:NVIDIA Nemotron 3 開放模型係列
全新的 Nemotron 3 開放模型係列 —— 包含 Nano、Super 和 Ultra 三種規模 —— 基於全新的異構潛在混合專家 (Mixture-of-Experts, MoE) 架構打造,帶來了兼具領先準確率與高效率的開放模型係列,非常適合用於構建代理式 AI 應用。
目前已發布的 Nemotron 3 Nano 30B-A3B 是該係列中計算效率最高的模型,針對軟件調試、內容摘要、AI 助手工作流和信息檢索等任務進行了優化,具備較低的推理成本。其異構 MoE 設計帶來以下優勢:
● 推理 token 數量最多減少 60%,顯著降低推理成本。
● 支持 100 萬 token 的上下文處理能力,使模型在長時間、多步驟任務中能夠保留更多信息。
Nemotron 3 Super 是一款麵向多智能體應用的高精度推理模型,而 Nemotron 3 Ultra 則適用於複雜的 AI 應用。這兩款模型預計將在 2026 年上半年推出。
NVIDIA 於 12 月 15 日還發布了一套開放的訓練數據集合集以及先進的強化學習庫。Nemotron 3 Nano 的微調現已在 Unsloth 上提供。
Nemotron 3 Nano 現可在 Hugging Face 獲取,或通過 Llama.cpp 和 LM Studio 進行體驗。
DGX Spark:緊湊而強大的 AI 算力引擎
DGX Spark 支持本地微調,將強大的 AI 性能集成在緊湊的桌麵級超級計算機形態中,讓開發者獲得比普通 PC 更多的內存資源。
DGX Spark 基於 NVIDIA Grace Blackwell 架構打造,最高可提供 1 PFLOP 的 FP4 AI 性能,並配備 128GB 的 CPU-GPU 統一內存,使開發者能夠在本地運行更大規模的模型、更長的上下文窗口以及更高負載的訓練工作。
在微調方麵,DGX Spark 可實現:
●支持更大規模的模型。參數規模超過 30B 的模型往往會超出消費級 GPU 的 VRAM 容量,但可以輕鬆運行在 DGX Spark 的統一內存中。
●支持更高級的訓練技術。完整微調和基於強化學習的工作流對內存和吞吐量要求更高,在 DGX Spark 上運行速度顯著更快。
●本地控製,無需雲端排隊。開發者可以在本地運行高計算負載任務,無需等待雲端實例或管理多個環境。
DGX Spark 的優勢不僅限於在 LLM 上。高分辨率擴散模型通常需要超過普通桌麵係統所能提供的內存。借助 FP4 支持和大容量統一內存,DGX Spark 可在短短幾秒內生成1000張圖像,並為創意或多模態工作流提供更高的持續吞吐量。
下表展示了在 DGX Spark 上對 Llama 係列模型進行微調的性能表現。
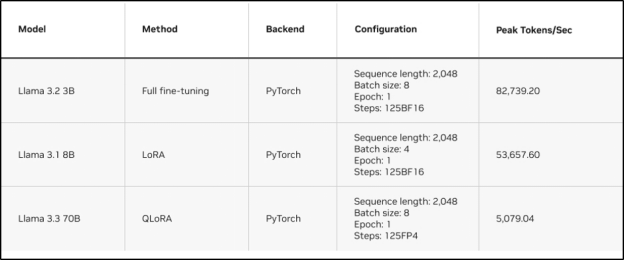
隨著微調工作流的不斷發展,全新的 Nemotron 3 開放模型係列為 RTX 係統和 DGX Spark 提供了可擴展的推理能力與長上下文性能優化。
#別錯過 — NVIDIA RTX AI PC 的最新進展
FLUX.2 圖像生成模型現已發布,並針對 NVIDIA RTX GPU 進行優化
Black Forest Labs 推出的新模型支持 FP8 量化,可降低顯存占用並將性能提升40%。
Nexa.ai 通過 Hyperlink 為 RTX PC 擴展本地 AI,實現代理式搜索
這款全新的本地搜索智能體可將檢索增強生成(RAG)索引速度提升3倍,將 LLM 推理速度提升2倍,使一個高密度1GB 文件夾的索引時間從約 15 分鍾縮短至僅 4 到 5 分鍾。DeepSeek OCR 現已通過 NexaSDK 以 GGUF 形式在本地運行,可在 RTX GPU 上即插即用地解析圖表、公式以及多語言 PDF。
Mistral AI 發布全新模型家族,並針對 NVIDIA GPU 進行優化
全新的 Mistral 3 模型從雲端到邊緣端均經過優化,可通過 Ollama 和 Llama.cpp 進行快速的本地實驗。
Blender 5.0 正式發布,帶來 HDR 色彩與性能提升
本次版本新增 ACES 2.0 廣色域/HDR 色彩支持,加入 NVIDIA DLSS,可將毛發與皮毛渲染速度提升最高達 5 倍,並改進了對大規模幾何體的處理能力,同時為 Grease Pencil 增加了動態模糊效果。




